 Long (Tony) Lian
Long (Tony) Lian
I am a Member of Technical Staff at Thinking Machines Lab, where I’m working on RL and post-training. I’m also an EECS PhD candidate at UC Berkeley and BAIR, advised by Prof. Adam Yala and Prof. Trevor Darrell. My research primarily focuses on developing LLMs/VLMs with reasoning capabilities through RL. I am also a research scientist intern at Meta GenAI with Victoria Lin and Yuandong Tian, working on reasoning LLMs. I interned with the Deep Imagination Research team at NVIDIA Research in 2024. I hold a B.A. in Computer Science from UC Berkeley, where I conducted research under the supervision of Prof. Stella Yu during my undergraduate studies. I also interned with Baidu’s Distributed Deep Learning team.
Publications (*: equal contribution)

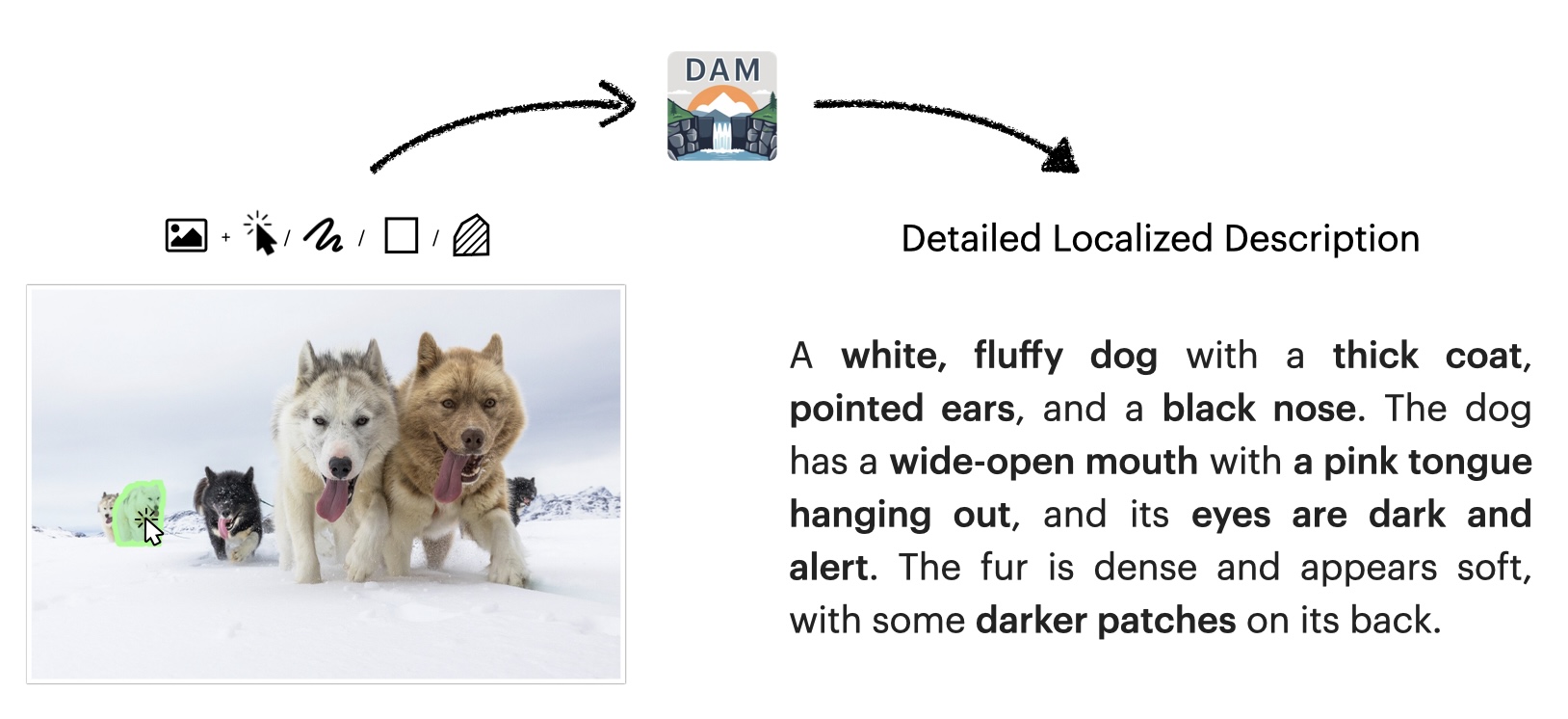
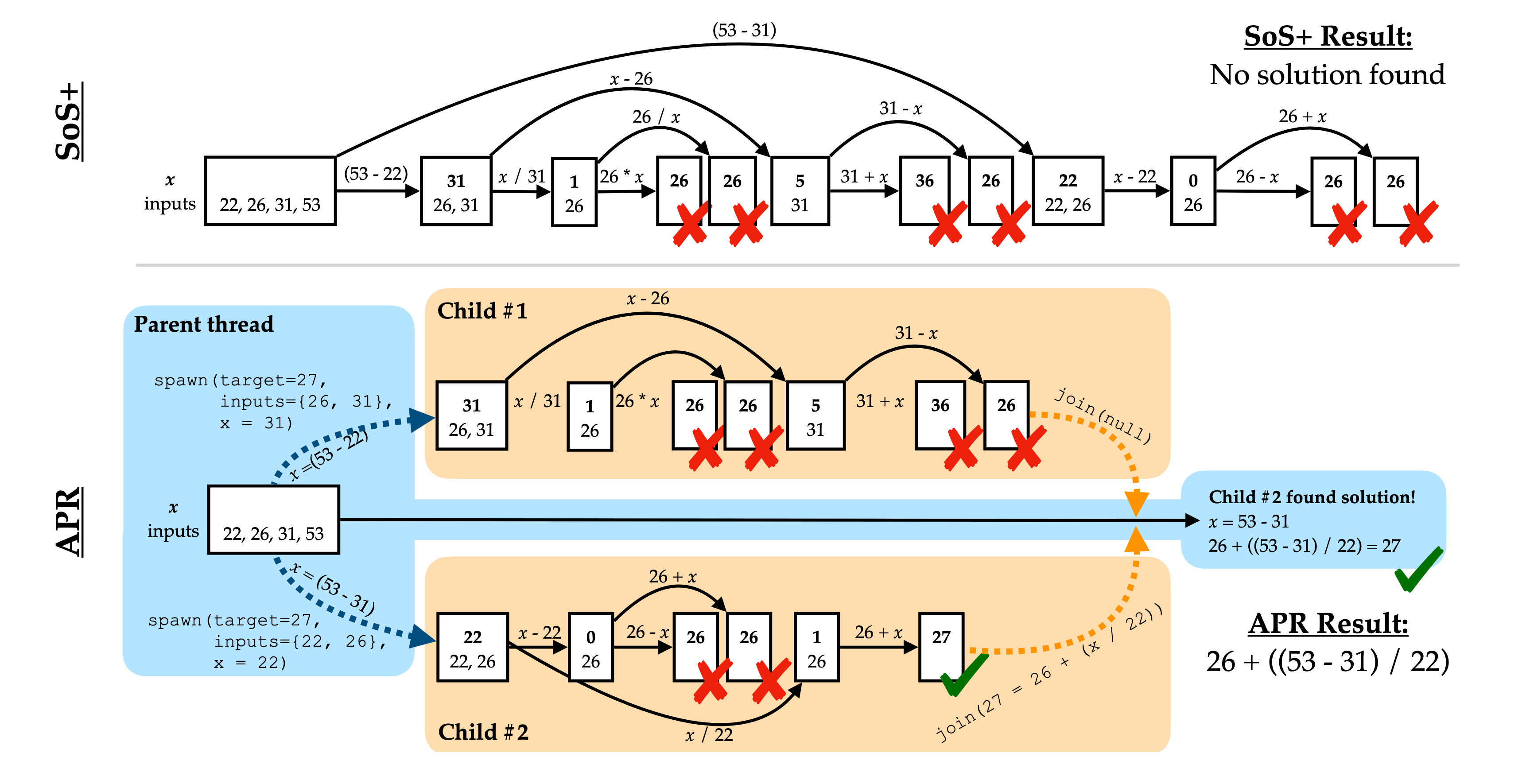
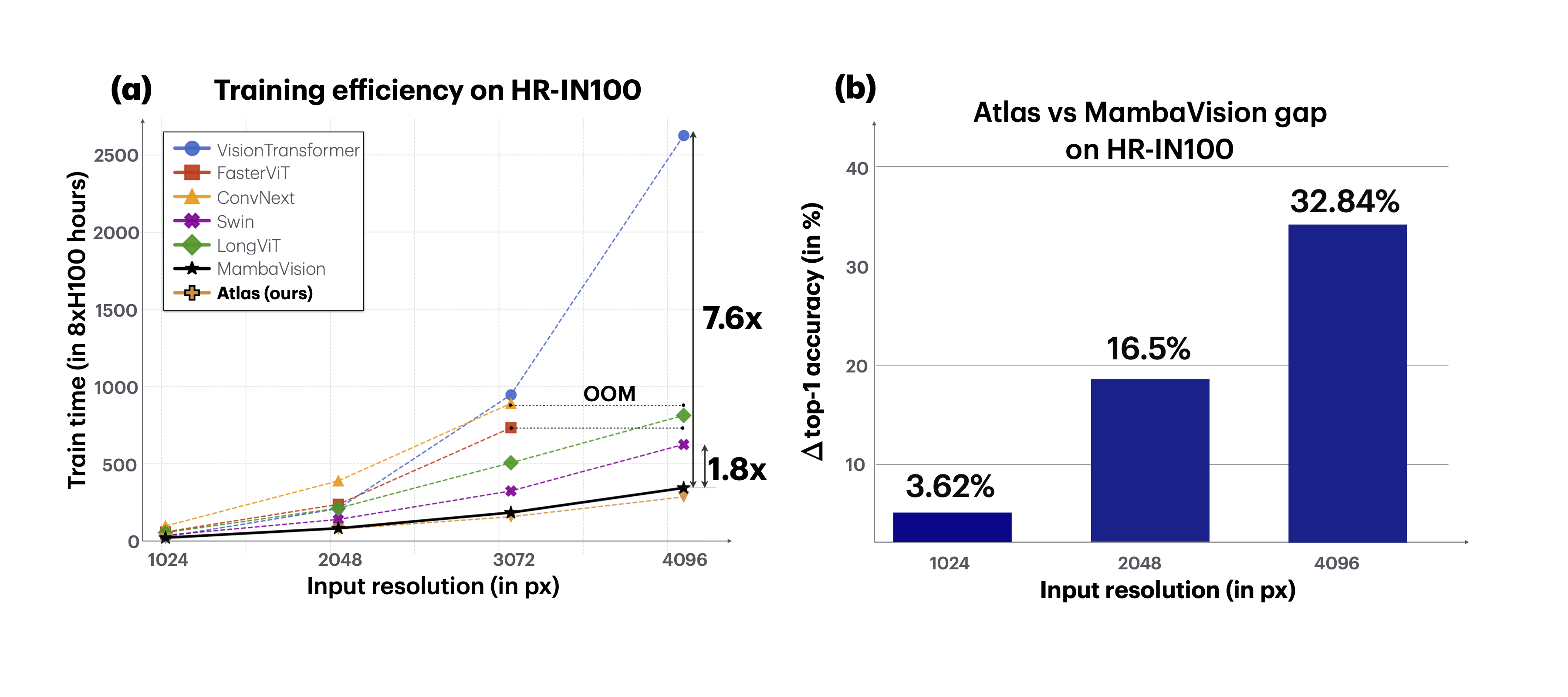
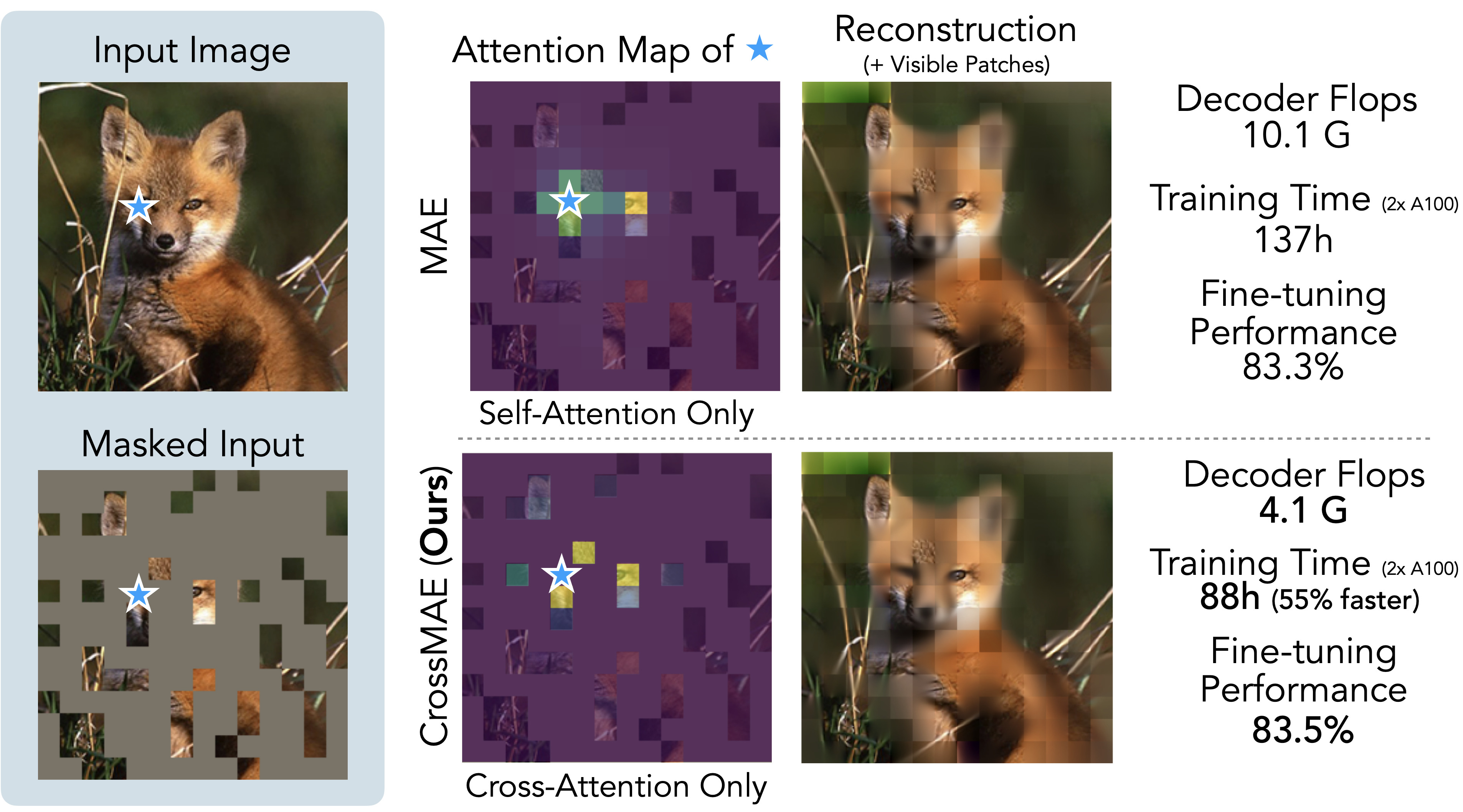

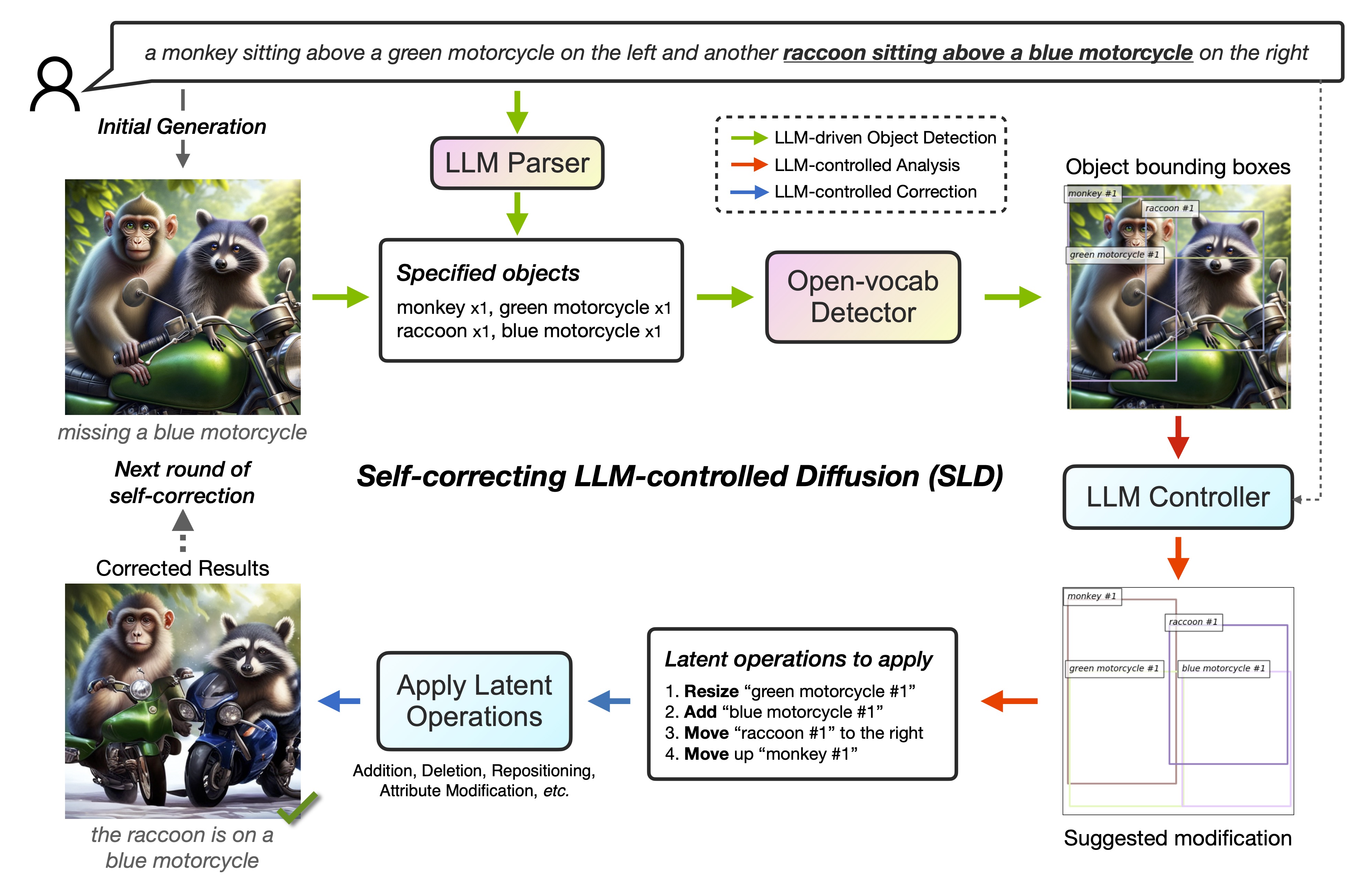
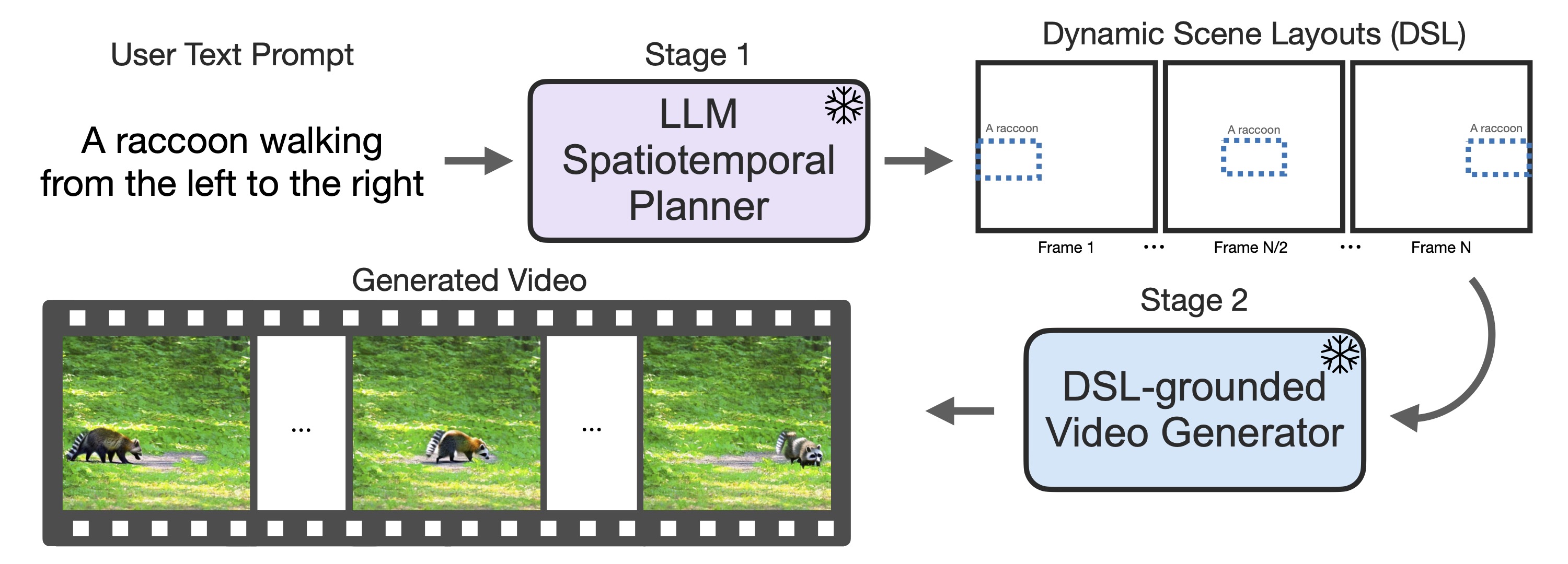

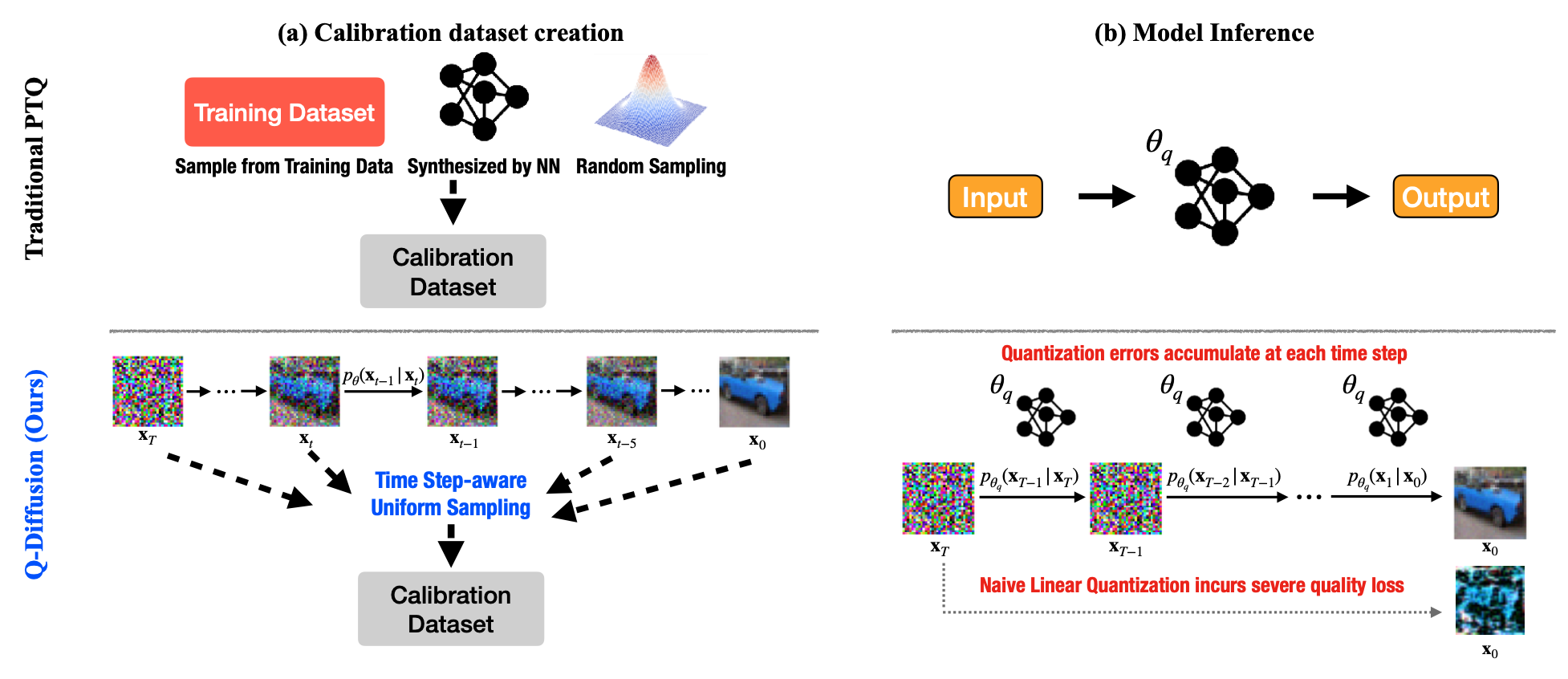

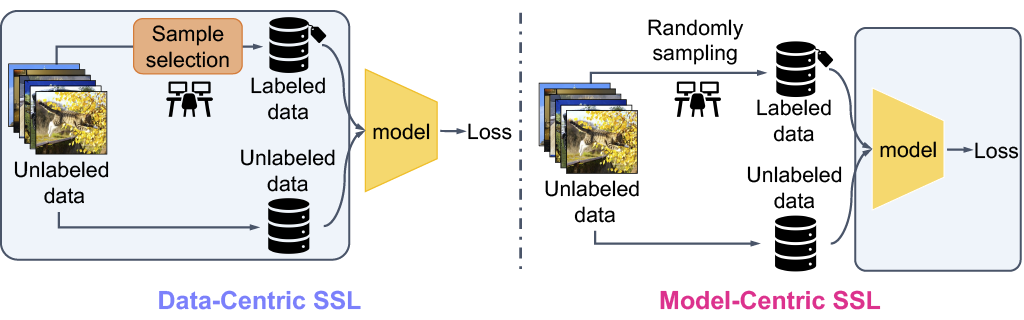
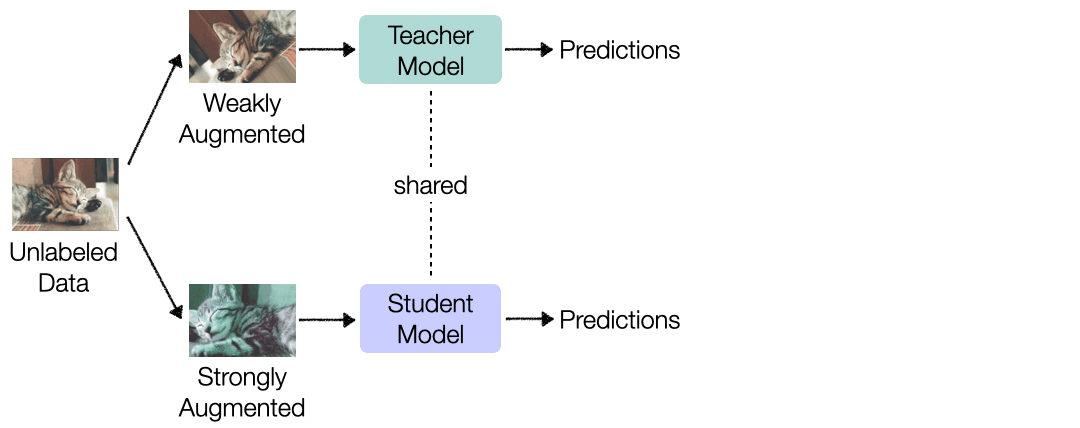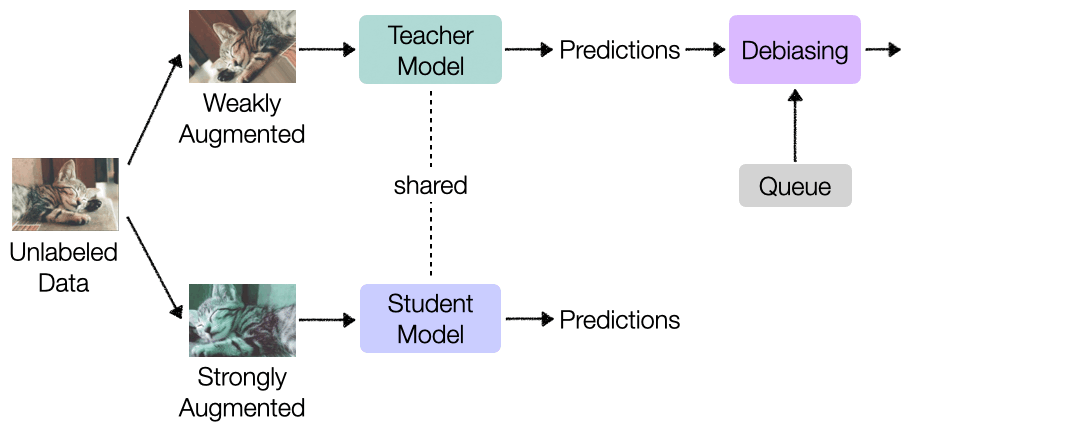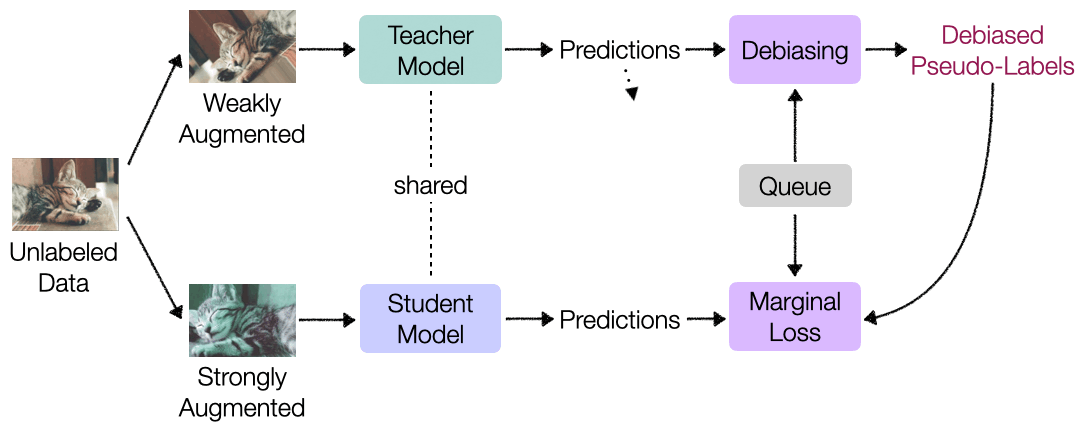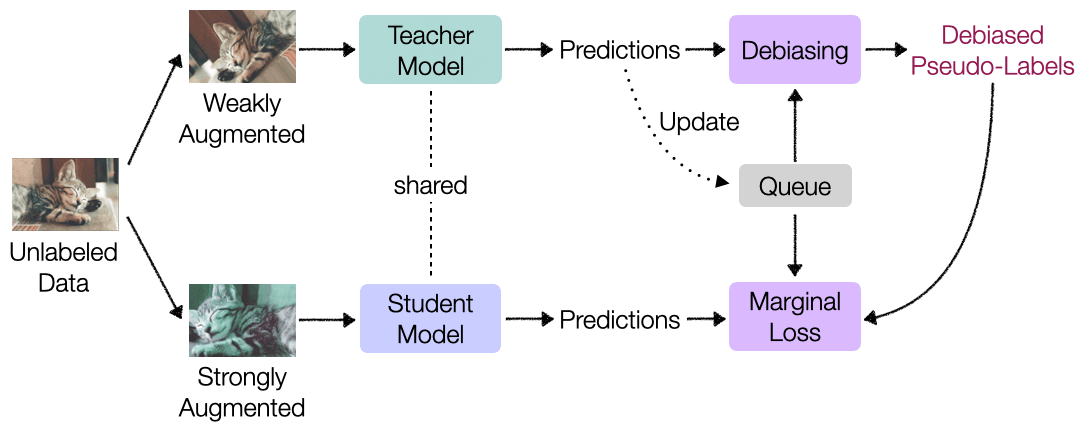

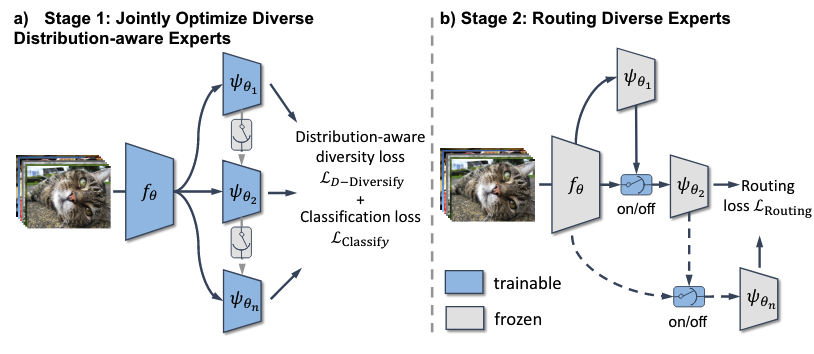
{kind=link}
{kind=link}
{kind=link}
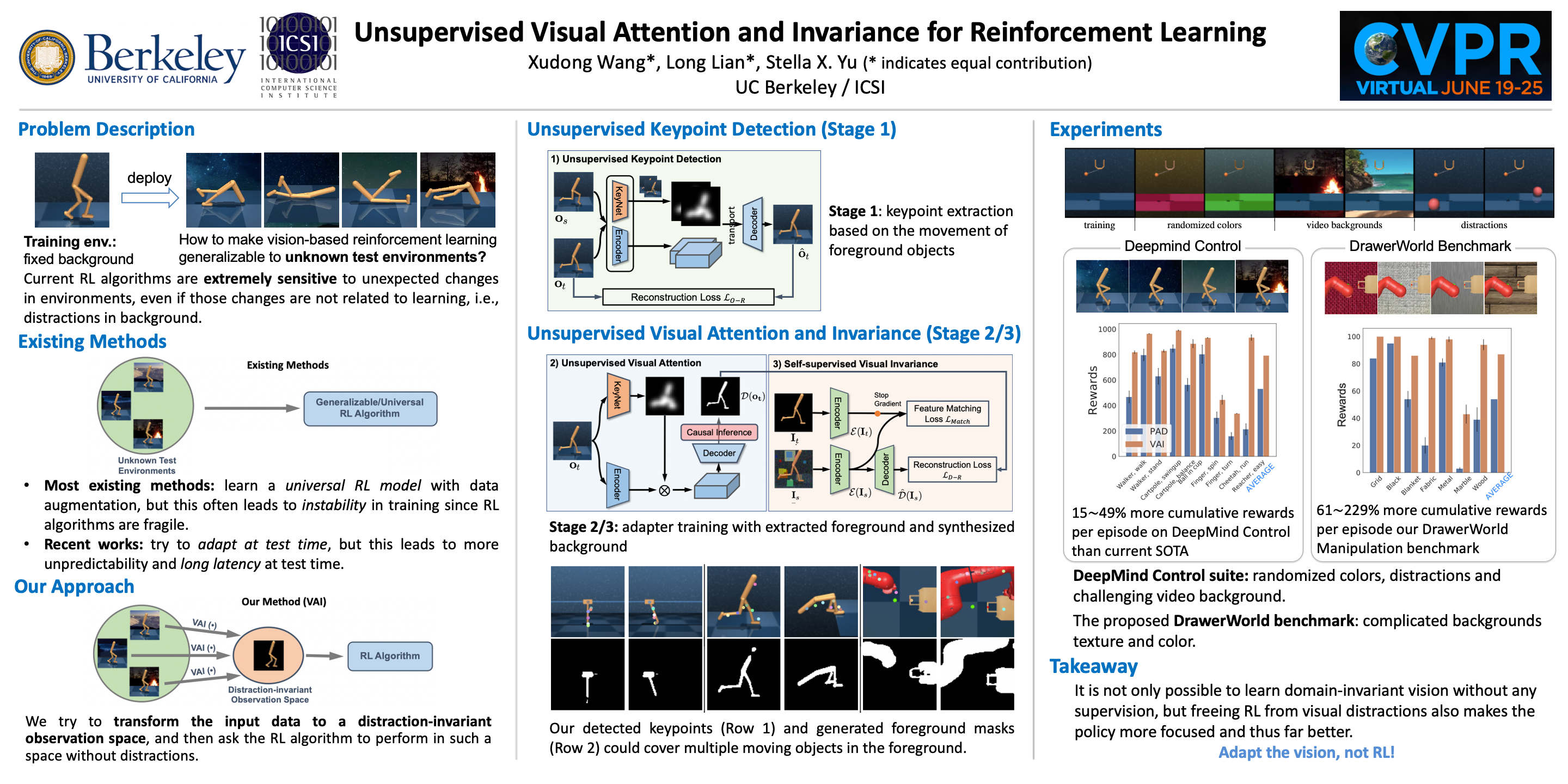{kind=link}
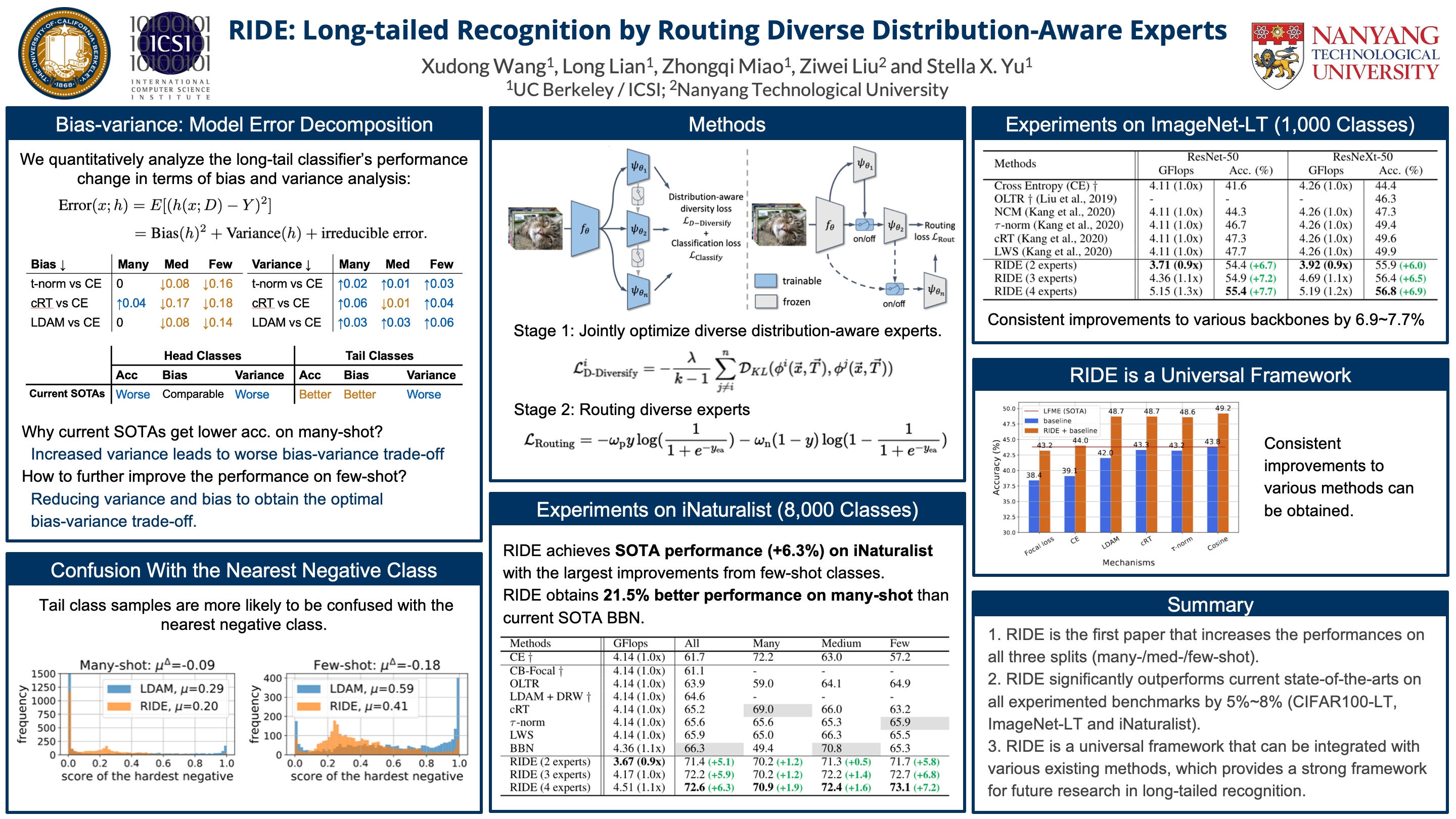{kind=link}
Academic Services
Reviewer for CVPR/ECCV/ICCV/ICLR/ICML/NeurIPS/AAAI